Transformer-Based OCR

As you probably already know, Optical Character Recognition (OCR) is the electronic conversion of images of typed, handwritten, or printed text into machine-encoded text. The source can be a scanned document, a photo of a document, or a subtitle text imposed on an image. OCR converts such sources into machine-readable text.
Let’s understand how an OCR pipeline works before we dig deeper into Transformer Based OCR.
A typical OCR pipeline consists of two modules.
1. A Text Detection Module
2. A Text Recognition Module

Text Detection Module
Text Detection module as the name suggests detects where text is present in the source. It aims to localize all the text blocks within the text image, either at word level (individual words) or text line level.
This task is comparable to an object detection problem only here the object of interest is the text blocks. Popular object detection algorithms include YOLOv4/5, Detectron, Mask-RCNN, etc.
To understand Object Detection using YOLO click here.
Text Recognition Module
Text Recognition module aims to understand the content of the detected text block and convert the visual signals into natural language tokens.
A typical text recognition module consists of two sub-modules.
1. Word Piece Generation Module
2. Image Understanding
The workflow under the text recognition module works as follows.
- The individual localized text boxes are resized to, let's say, 224x224 and passed as input to the image understanding module which is typically a CNN module (ResNet with self-attention).
- The image features from a particular network depth are extracted and passed as input to the Word Piece Generation Module, which is an RNN based network. The output of this RNN network is machine-encoded texts of the localized text boxes.
- Using an appropriate loss function, the Text Recognition Module is trained until the performance reaches an optimal scale.
What makes transformer-based OCR different?
Transformer-based OCR is an end-to-end transformer-based OCR model for text recognition, this is one of the first works to jointly leverage pre-trained image and text transformers.
Transformed-based OCR looks like the diagram below. The left-Hand side of the diagram is the Vision Transformer Encoder and the Right-Hand side of the image is the Roberta (Text Transformer) Decoder.
ViTransformer or Encoder :
An image is split into NxN patches, where each patch is treated similarly to a token in a sentence. The image patches are flattened (2D → 1D) and are linearly projected with positional embeddings. The linear projection + positional embeddings are propagated through the transformer encoder layers.
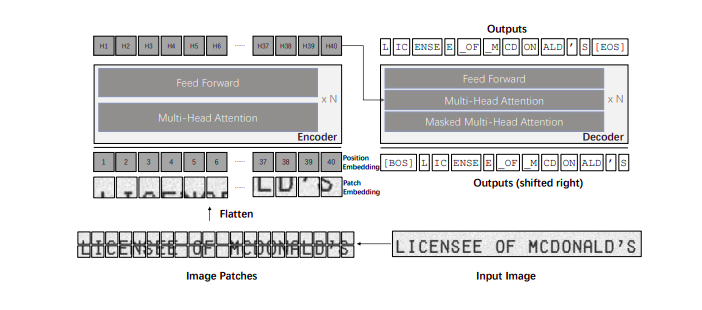

In the case of OCR, the image is a series of localized text boxes. To ensure consistency in localized text boxes, the images/image region of the text boxes are resized to a HxW. After which the image is decomposed into patches, where each patch size HW/(PxP). P is the patch size.
After that, the patches are flattened and linearly projected to a D-Dimensional vector which are patch embeddings. The patch embeddings and two special tokens are given learnable 1D position embeddings according to their absolute positions. Then, the input sequence is passed through a stack of identical encoder layers.
Each Transformer layer has a multi-head self-attention module and a fully connected feed-forward network. Both of these two parts are followed by residual connection and layer normalization.
Note: Residual connections ensure gradient flow during backpropagation.
Roberta or Decoder :
The output embeddings from a certain depth of the ViTransformers are extracted & passed as input to the decoder module.
The output embeddings from a certain depth of the ViTransformers are extracted and passed as input to the decoder module.

The decoder module is also a transformer with a stack of identical layers that have similar structures to the layers in the encoder, except that the decoder inserts the “encoder-decoder attention” between the multi-head self-attention and feedforward network to distribute different attention on the output of the encoder. In the encoder-decoder attention module, the keys and values come from the encoder output, while the queries come from the decoder input.
The embeddings from the decoder are projected from the model dimension (768) to the dimension of vocabulary size V (50265).
The softmax function calculates the probabilities over the vocabulary and we use beam search to get the final output.
Advantages:
- TrOCR, an end-to-end Transformer-based OCR model for text recognition with pre-trained CV and NLP models is the first work that jointly leverages pre-trained image and text Transformers for the text recognition task in OCR.
- TrOCR achieves state-of-the-art accuracy with a standard transformer-based encoder-decoder model, which is convolution free and does not rely on any complex pre/post-processing step.
References:
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models https://arxiv.org/pdf/2109.10282.pdf
An image is worth 16X16 words: Transformers for Image Recognition at Scale https://arxiv.org/pdf/2010.11929v2.pdf



Comments
Post a Comment